A story of staying within budget during migration to BigQuery
Balázs Varga
11 min read
Written by Balázs Varga
When migrating your data warehouse to GCP, you will inevitably face some of the common pitfalls of the cloud, alongside the usual difficulties of a migration project. Instead of trying to catch up with these issues after the fact, it is critical to have the right support during the migration process itself. Read a true story below.
One of the challenges of our customers has been keeping the costs at bay, as the budget allocated to the migration project is tight.
The decision-makers at the company want to anticipate how much recurring monthly expenses they can expect once the migration is complete, before giving the green light to migrate everything.
Keep reading to find out how Rabbit was able to help during this migration, and how it can also help your company save thousands of dollars on BigQuery costs.
Company profile
One of our customers is developing a social networking site used by over 20 million people. They had started to migrate their data teams’ pipelines of Hive workloads to BigQuery in order to reduce the load on their on-prem cluster, opening up the possibility of downsizing it in the future.
Hive is an on-premise, Hadoop-based data warehouse system. SQL is used to perform data transformations, but the dialect and the supported features are slightly different from BigQuery. The migration involved copying the base datasets to BigQuery, translating the SQL transformations, and validating the resulting data against the original on-prem results. The translation was a partially automated process, but it still required a ton of manual work.
The customer was cost-conscious and wanted to have a full understanding of what the biggest cost drivers would be.
Understanding the costs
The migration lasted over 6 months and ended up being more complex than initially anticipated. The translation of the queries required many iterations, until the results could be validated, and this required the engineers to rerun the pipelines dozens of times. The GCP costs skyrocketed. During the migration, BigQuery compute costs were in the range of $20-25k/month, while storage costs were between $5-10k monthly. They wanted to understand the generated costs better:
- What are the most expensive queries? How do costs compare to on-prem costs?
- Are the majority of the costs generated by already scheduled production workloads? Or are these only development (“staging”) costs that would subside once everything has been migrated?
- Whoa, what was that $2000 spike on Tuesday? How can we prevent this from happening again?
Diving into the costs
The customer was using slot-based pricing with reservations, so the default GCP billing dashboards and exports were not very helpful in figuring out the compute costs of individual queries. The billing is done per reservation, project, and location, based on the utilized slot-hours, so the cost breakdown looks something like this:
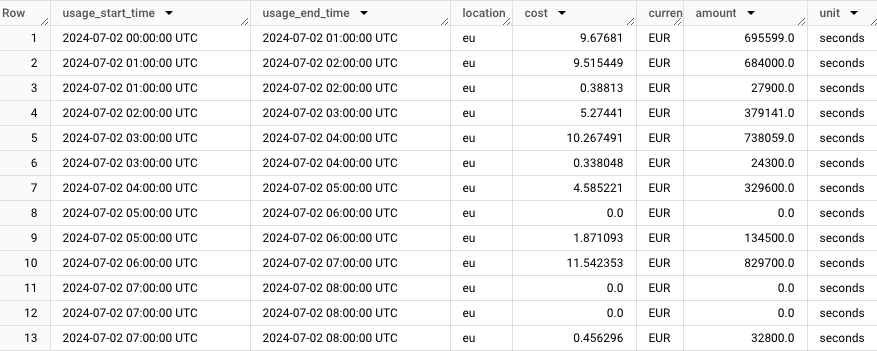
Rabbit calculates the true costs of the individual jobs based on the slot-hours they consume. Optionally, it can aggregate multiple executions of the same query.
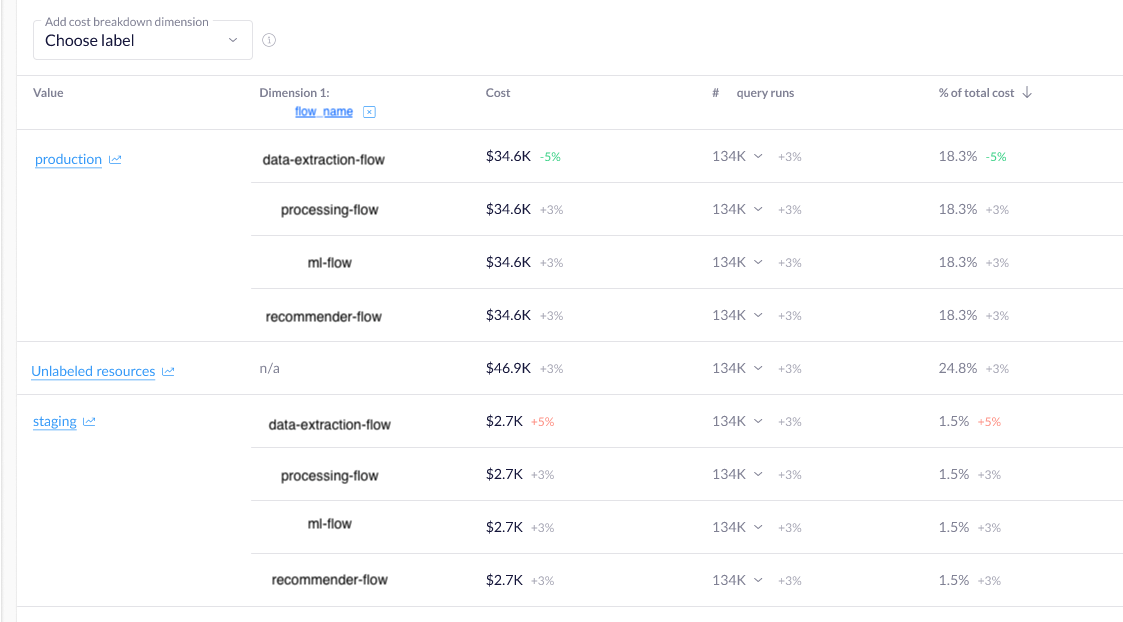
The BigQuery jobs of this customer were executed as parts of pipelines, consisting of not only these queries but also Flink jobs running on a GKE Autopilot cluster, data ingestion or extraction steps, as well as data quality checks and validations. The pipelines consist of these steps, organized in a directed acyclic graph based on their dependencies on each other. The workflows are executed by an orchestrator, similar to Apache Airflow or Argo Workflows. Our customer had done a great job of labeling their queries: each one contained information about the name of the workflow, the name of the step, whether it was a production or development run, etc. Due to this diligent labeling, they were able to use Rabbit to look at the cost summaries of whole flows, not just the individual queries.
Comparing the on-prem resource utilization of a flow with the total cost of the migrated workflow, they were able to extrapolate how much their total footprint would be after migrating the remaining on-prem flows.
Based on the “Labels” view of Rabbit, it was easy to answer how the cost of a flow evolves over time. In an upcoming version of Rabbit, they will even be able to do a multi-level cost breakdown of labels, such as grouping by the “flow” and “step” labels hierarchically.
Finding and preventing anomalies
Rabbit is not only a cost-monitoring tool, but a complete solution to regain control of your spending. Let’s take a look at how we can help to prevent cost spikes.
Some of the queries made use of BigQuery Remote functions, which were backed by a Cloud Function. BigQuery would call the function via an HTTP request, which is answered by one of the many instances of the function, running in a container.
One of the queries was translated suboptimally. BigQuery was not able to batch the rows when calling the function, meaning that it fired a new request for each of the millions of rows. This has caused the function to scale up to its maximum number of instances, and stay there until the job timed out or finished.
This problem was quickly caught by Rabbit’s anomaly detection.
The first thing it detected was the excessive cost of logging that was generated by the Cloud Function. The cost was also visible in the BigQuery reservation’s usage.
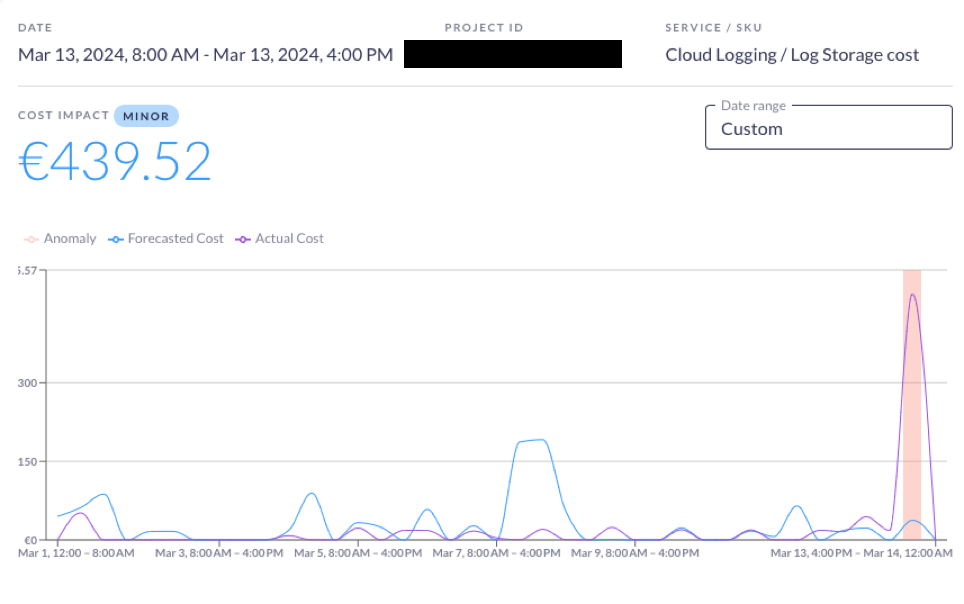
The next day, engineers were able to investigate the root cause, rewrite the problematic query, and tune the parallelism settings of the Cloud Function. They have also decided to introduce a lower job timeout to prevent such anomalies. This has prevented the issue from continuing to draw a large cost daily.
Playing with reservations…
Most of the cost spikes happened when running “staging” workflows. That is, running the flows that are past their initial development stage, on a copy of production data. These ad-hoc executions and data quality checks needed to pass successfully before promoting and scheduling the workflow to production.
The customer’s reservation setup was simple: the staging and prod jobs were executed from the same project, using the same reservation. This could scale up to 4900 slots and had no baseline slots reserved.
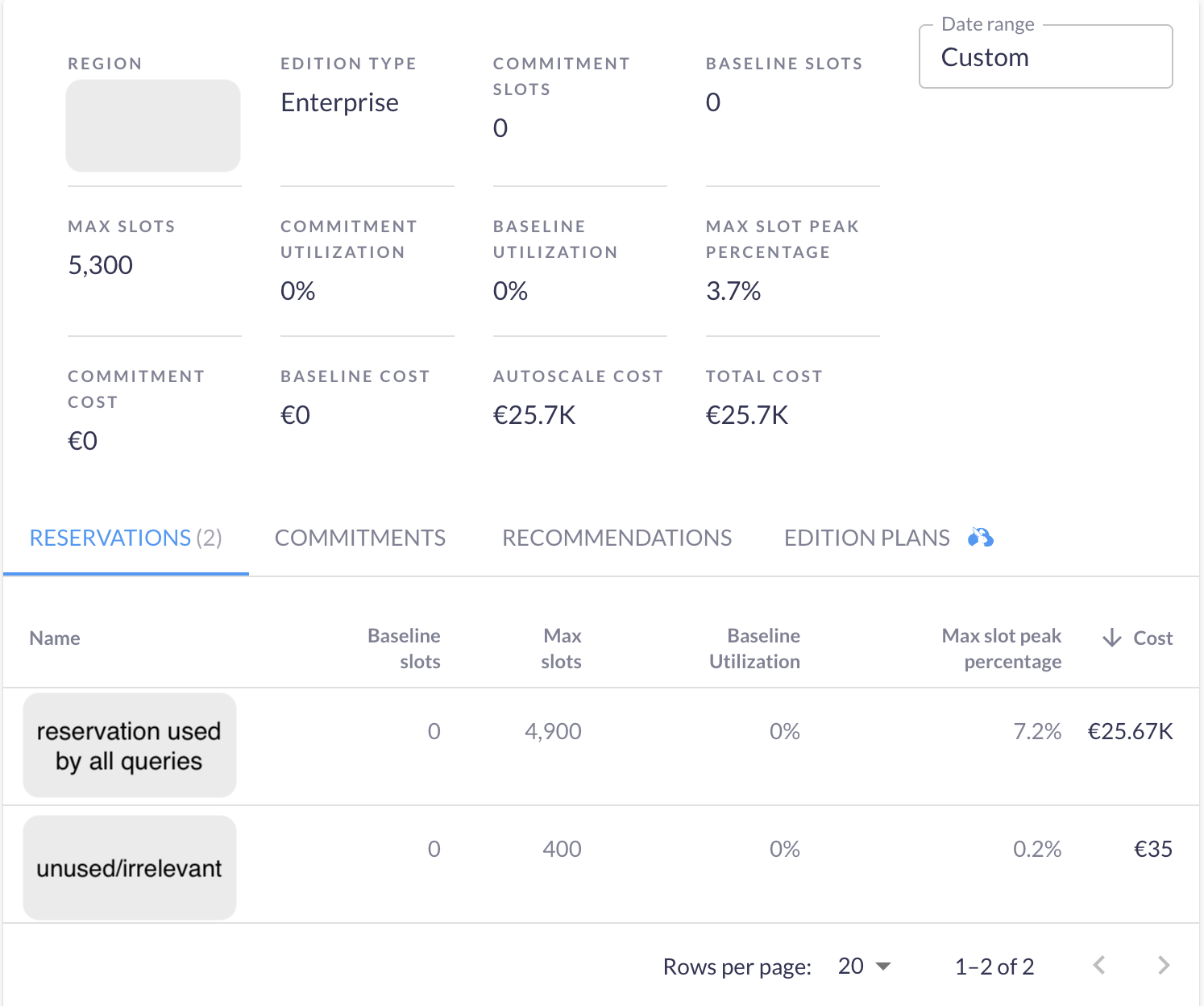
In Rabbit, we saw that the slots were usually underutilized, but there were a few peak periods when the utilization matched the limit (see the p90 line on the graph). In the average and median cases though, a lower limit of slots would have sufficed.
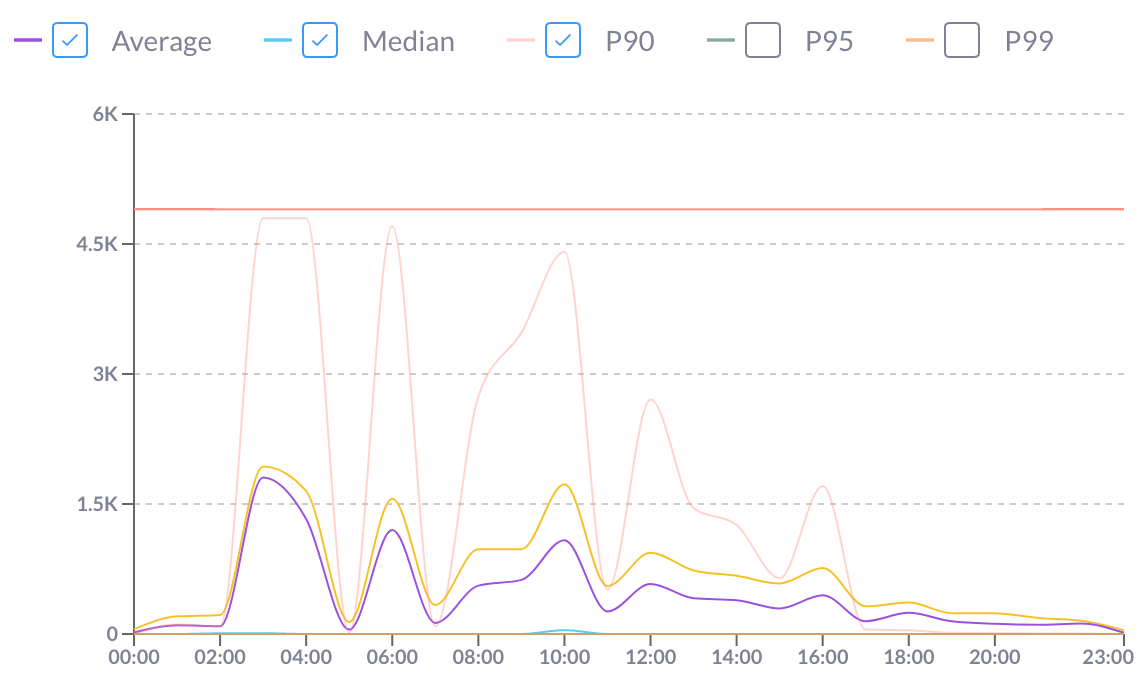
We have suggested a setup of different reservations for the 3 different kinds of workloads:
- Scheduled, production workloads: These could remain a relatively large reservation, with maybe 2000 slots. This would still allow the scheduled workloads to finish on time.
- Staging workloads: These would be assigned a smaller reservation (e.g. 300), setting the slots so that the workloads under validation can complete in the required time.
- Dev workloads would get a reservation as small as possible, without affecting developer productivity.
With slot-based pricing, this can be an effective way of maximizing accidental spending. For example, let’s say the “staging” reservation is set to 300 slots. Priced at $0.06 / slot-hour, a rogue query accidentally running for 6 hours (the maximum timeout), could cause a spike of $108. Still painful, but way less than $1728 in the original setup.
…or going without reservations?
While it might seem like a no-brainer to use reservations once you’re a “large” customer, this is not always the case. Turns out, you should do some calculations. We have used the data collected by Rabbit to compare the current (slot-based) costs of each query with the price calculated based on the processed data, if they were using on-demand pricing.
One of the most interesting findings we had when working with this client is that some of their jobs would be much better off if they were using on-demand pricing.
In the most extreme case, a job currently costing more than $5600 a month could be executed for just 4 dollars monthly with on-demand pricing. That’s a pretty huge difference.
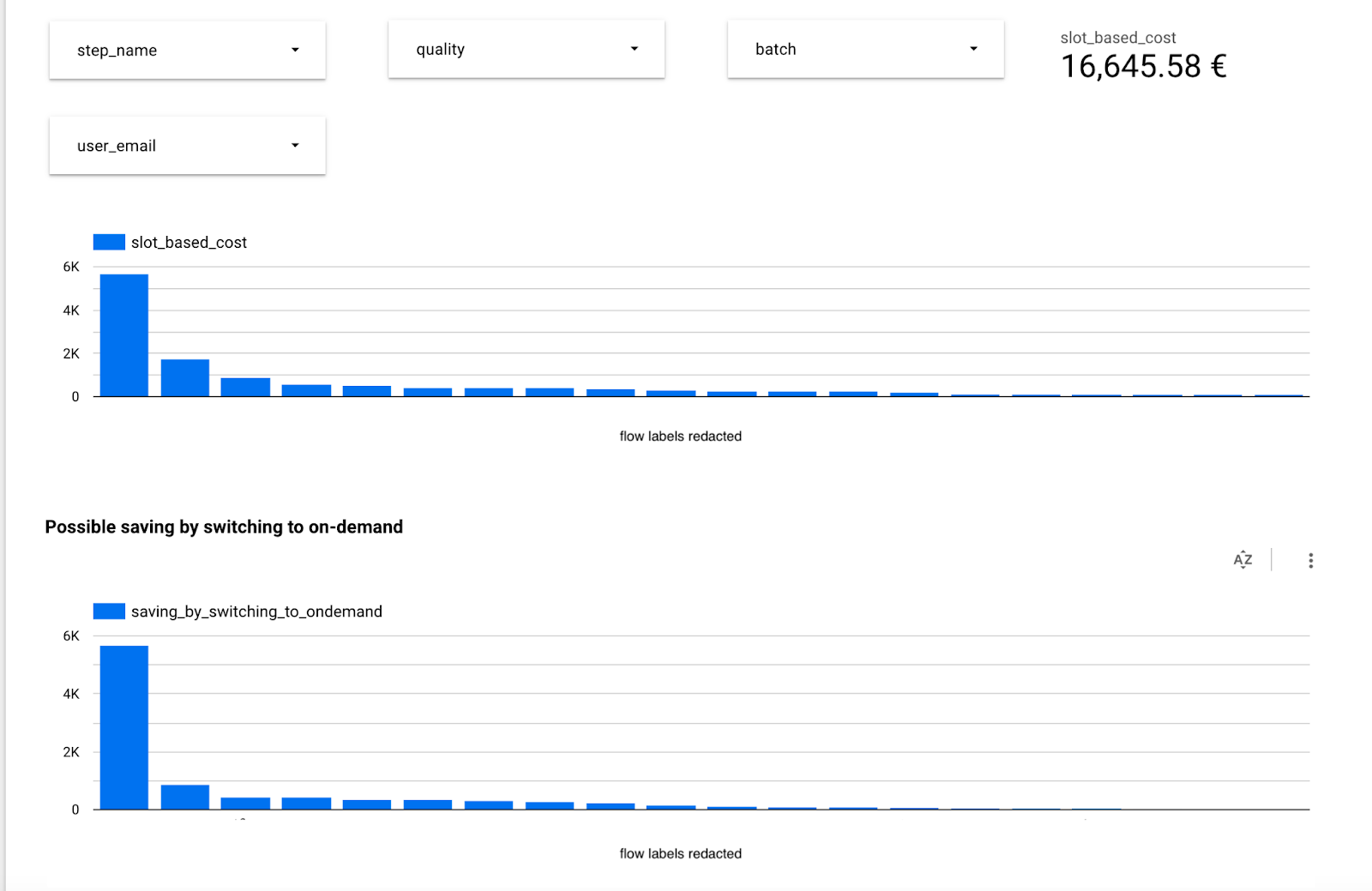
Why is this the case? Well, without going into specifics, self-joins can cause processing time and cost to explode, but the data being read from the table remains small (and this is what you’re billed for with on-demand pricing).
So to act on this, we have suggested creating a new project, outside of any reservations (be careful, if a project is within a folder or organization, it will inherit the parent’s reservation by default - so this must be explicitly set to none, or be put outside of the folder). By moving just the top 5 suggested workflows, this client could save more than $7k a month on their compute costs.
In general, you might still want to stay on slot-based pricing, these examples here are the outliers. Also, remember that on-demand pricing has its limitations, such as the 2000-slot limit imposed by BigQuery.
Rabbit can help you decide which pricing model is the most cost-effective for your team, even at the level of individual queries. In the upcoming version, you will find recommendations to make this choice, and you’ll be able to view the alternative costs in the labels view.
For the workloads that will stay in slot-based pricing, we recommend using Rabbit’s reservation planning features to select a commitment and obtain the best price.
Storage
Compute costs are only one side of the story. The customer’s data warehouse was built around daily data, meaning that each day, new versions of tables were calculated, with older snapshots being retained for a few weeks. This meant that they were storing multiple versions of data at once. This can add up to a lot of storage cost.
Rabbit has helped in multiple ways. First off, BigQuery offers two storage pricing models: logical and physical. With logical pricing, you pay for the uncompressed size of the table, but you’re not billed for storage used for time travel. If you use physical billing, the compressed size of your data is billed (but the rate is twice that of the logical), and you pay for storing the data required for time travel.
Which one is cheaper depends on your data. If the data compresses well, and your time travel window is short, you will likely benefit from physical billing. If you need a long time travel window, or the table is modified frequently, so that the size of the time travel data is large, logical billing might be better.
In the case of our customer, Rabbit has provided suggestions about this, helping the customer decide which pricing model to choose for each dataset. Rabbit constantly evaluates the two options, and offers new recommendations in case the circumstances change.
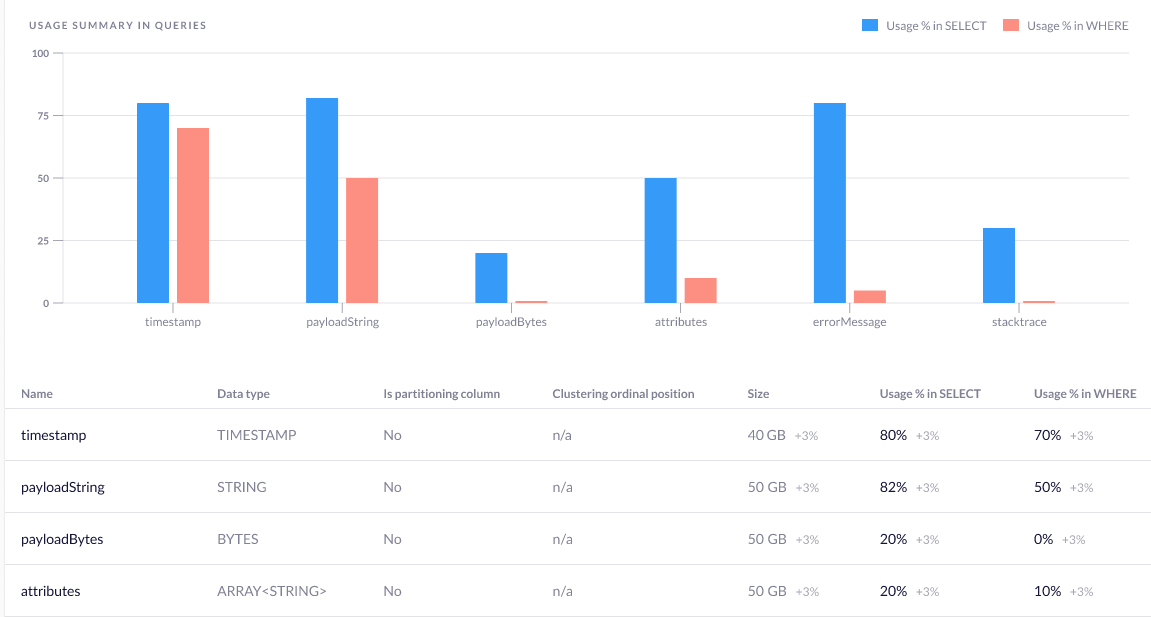
Rabbit also knows about the patterns of how you query various columns of the tables. It can make recommendations about partitioning and clustering, based on this information.
Rabbit was also used to monitor the overall costs of datasets. It has helped to identify an issue that could have caused a huge runaway cost: some of the datasets were created without any retention settings. This meant that the daily snapshot tables kept piling up, the size of the dataset growing with each execution.
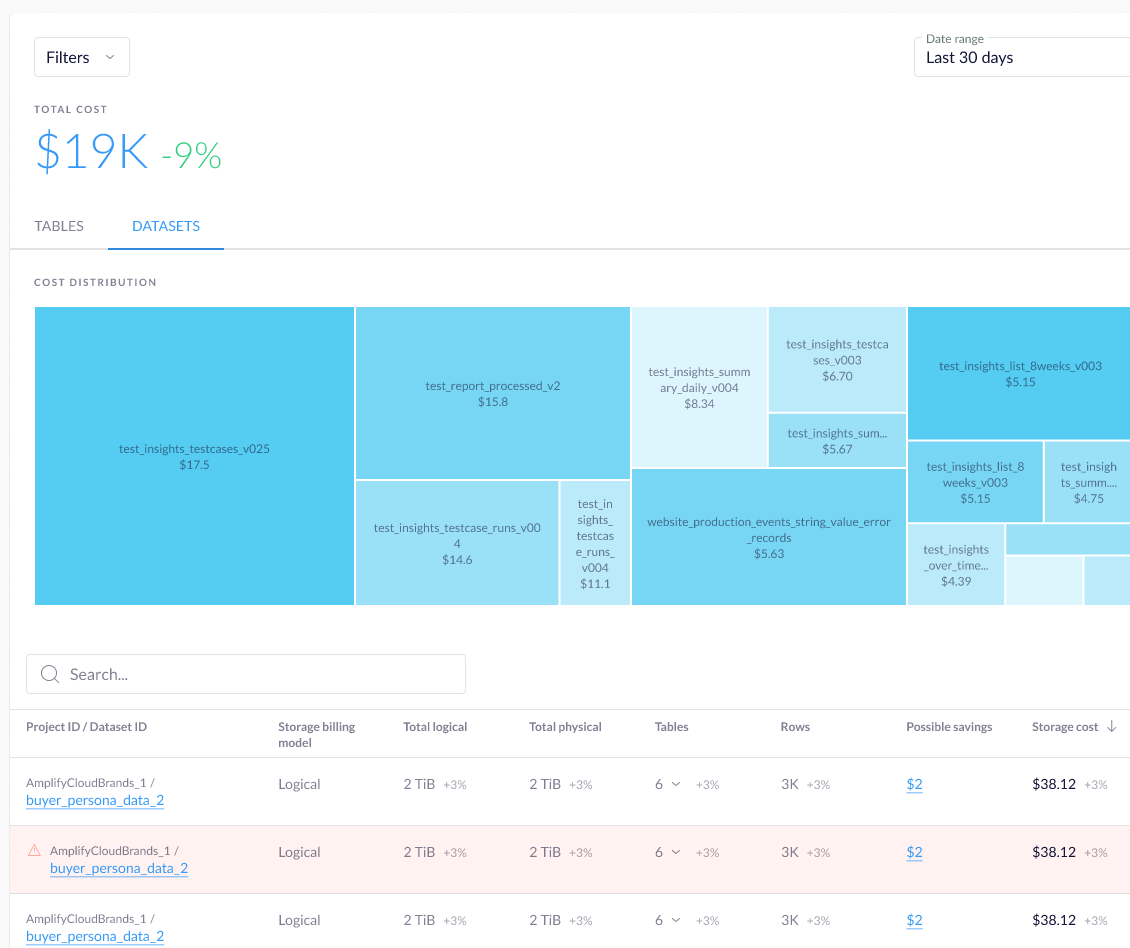
After noticing the growing cost on Rabbit, the engineers identified thousands of old tables that were no longer needed, freeing up over 100 TB of storage space, saving thousands of dollars monthly. They’ve reviewed the retention settings of the datasets to ensure that this wouldn’t happen again.
With Rabbit, you can maintain control over your BigQuery costs when migrating from an on-prem data warehouse. Its advanced recommendations and superior monitoring capabilities allow you to fine-tune your configurations, catch anomalies, and understand your spending.
Sign up for a free trial, or contact us to try Rabbit on demo data.


'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M45.5%2025.5518L34.1769%2038.2287L32.7627%2036.8145L45.5%2025.5518Z'%20fill='white'%20stroke='white'%20stroke-width='0.5'%20stroke-linejoin='round'/%3e%3cpath%20d='M70.5152%2014.3181C73.7912%2020.0199%2075.5103%2026.4829%2075.5%2033.0589C75.4896%2039.6349%2073.7502%2046.0925%2070.4563%2051.784C67.1624%2057.4755%2062.4297%2062.2008%2056.733%2065.4858C51.0363%2068.7708%2044.576%2070.5%2038%2070.5'%20stroke='%23369AF8'/%3e%3cpath%20d='M0.500329%2032.8429C0.527791%2026.287%202.27351%2019.8528%205.56339%2014.182C8.85327%208.51124%2013.5723%203.80204%2019.25%200.524045'%20stroke='%23369AF8'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_13001_7939'%20x1='22.5'%20y1='48.5356'%20x2='49.5016'%20y2='48.5356'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%239B51E0'%20stop-opacity='0.8'/%3e%3cstop%20offset='1'%20stop-color='%23369AF8'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)